标题:TMS320C6000系列DSP的软件优化技术
|
1 DSP系统的软件优化流程 DSP系统的软件优化流程如图1所示。整个工作流程分为3个阶段:
第1阶段,直接根据需要用高级C语言实现DSP功能,测试代码的正确性。然后,移植到C6X平台,利用C6X开发环境Profile测试程序的运行时间。若不满足要求,则进入下一阶段。 第2阶段,利用C6X提供的优化方式和其他各种优化技巧,如使用不同的编译器选项使能软件流水,循环展开,字存取代替半字存取等,优化C语言代码。如果还不能满足要求,则进入第3阶段。 第3阶段,将C语言代码中耗时最长的部分抽取出来,用线性汇编语言重写,用汇编优化器进行优化。使用profile确定这段代码是否需要进一步优化。 2 优化过程 首先,用C语言编写程序,并通过编译验证其正确性。然后,使用内联函数和合适的优化选项进行优化,并通过CCS中的profiler确定是否有函数需要被进一步优化,使用线性汇编语言重写需要被优化的函数。最后,使用汇编优化编程技巧和汇编优化器优化汇编代码。 2.1 编译器 当优化器被激活时,将完成图2所示的过程。C/C++语言源代码首先通过一个完成预处理的解析器(Parser),生成一个中间文件(.if)作为优化器(Optimizer)的输入。优化器生成一个优化文件(.opt),这个文件作为完成进一步优化的代码生成器(Code generator)的输入,最终生成汇编文件(.asm)。当选择编译选项时,-o2和-o3将尽可能地优化软件。
2.2 编译器内联函数 TMS320C6X提供了很多内联函数,它们直接映射为内嵌C6X汇编指令的特殊函数,这样可迅速优化C语言代码。C编译器以内联函数的形式支持所有C语言代码不易表达的指令。内联函数用下划线"_"开头,如例2,使用时如同调用普通函数一样。下面结合实例,研究一下完成200点点积经过上述各种优化技术优化后的代码效率。完成200点的点积运算C语言代码程序dotp.c如下: 
3 线性汇编代码的优化 优化线性汇编代码,首先是尽可能地使指令并行,使得同一时间内多个功能单元同时被使用,然后是调整代码顺序,缩减等待时延(NOPS),如例5。接下来使用字访问short型数据,如例6,最后使用软件流水技术。当进行实际操作时,并不是要按顺序地完成上面的每一步。只要达到要求,就可以结束。 3.1 C语言代码转换到线性汇编代码 定点点积中,C语言代码内部循环使用线性汇编指令,如例3所示。
①装载指令(LDW)必须使用.D单元。 ②乘法指令(MPY和MPYH)必须使用.M单元。 ③加法指令(ADD)使用.L单元。 ④减法指令(SUB)使用.S单元。 ⑤跳转指令(B)使用.S单元。 由此得到例4的汇编代码。 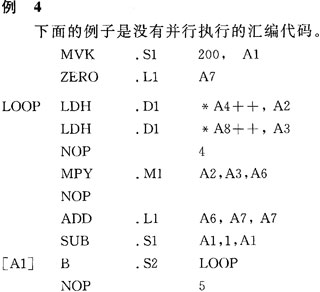 完成200次循环迭代,经过profile clock分析循环部分,需要16×200=3200 cycles。 3.3 使用并行指令完成点积代码 使用并行指令完成点积代码如例5所示。  使用并行指令,循环体内需要8个时钟周期。这段循环代码的执行周期为8×200=1600 cycles。 3.4 使用字存取原short型数据 为进一步提高效率,使用字存取原short型数据,如例6所示。 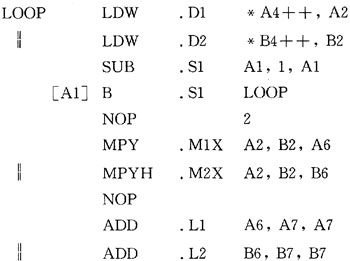 这段代码在循环体内仍然是8个时钟周期,迭代100次为8×100=800 cycles。 4 软件流水技术 软件流水技术是用在循环语句中调用指令的方法,即安排循环中的多个迭代运算并行执行。在编译C语言代码时,可以选择编译器的-o2或-o3选项,编译器将根据程序尽可能地安排软件流水。图3所示为运用软件流水的循环结构,它包括A、B、C、D、E五次迭代,同一周期最多执行五次迭代的不同指令(阴影部分)。图3中阴影部分称为"循环内核",核中不同的指令并行执行。核前执行的过程称为"流水线填充",核后执行的过程称为"流水线排空"。
在画相关图时应遵循: ①画出节点和路径; ②写出完成各指令需要的CPU周期; ③为各节点指派功能单元; ④分开路径,以使最多的功能单元被使用。 根据相关图写出模迭代间隔安排表,如表1所列。
 由此得到的代码所需CPU时钟周期为7+100+l=108 cycles。 5 总 结 各种优化技术所需时钟数如表2所列。表中括号内数字为循环内核时钟周期,括号前数字为流水线填充时钟周期,括号后数字为流水线排空CPU时钟周期。
| |||||||







